

Abstract
Introduction:Valuable research data is limited in its use when it is unstructured and not stored in discrete meaningful fields. Reports of the bone marrow (BM) aspirate and biopsies performed in patients with suspected or confirmed myeloid neoplasms typically include blood counts, peripheral blood (PB) and BM aspirate/touch preparation differential counts, morphological interpretation of aspirate and core biopsy and ancillary data such as karyotype, fluorescent in situ hybridization (FISH) and molecular mutations. Final BM reports are typically reported in a semi-structured document that are sufficient for a single patient review but inadequate for large scale queries to identify patients with a specific diagnosis or capture important diagnostic data. Manual extraction of these fields is expensive, time consuming and error prone. The aim of this study is to develop a customized algorithm for automated extraction of data from bone marrow biopsy reports and generate a framework that allows us to perform large-scale queries.
Methods:We randomly identified 148 patients with a diagnosis of a myeloid neoplasm: chronic myeloid leukemia (n=45), chronic myelomonocytic leukemia (n=54) and acute myeloid leukemia (n=57). Seven patients included in this analysis were initially diagnosed as CMML and subsequently transformed to acute myeloid leukemia. Total number of reports evaluated was 524. Numerical and text diagnostic data were extracted manually from the entire cohort selected, which is considered a gold standard. A customized rule based algorithm was developed for each data attribute using Natural Language Processing (I2E Text Mining platform, Linguamatics Ltd, Cambridge, UK). Numerical data captured included differential counts from peripheral blood, bone marrow aspirate or touch preparation. Diagnostic data was captured as included diagnostic interpretation of peripheral blood smear and bone marrow aspirate. The algorithms for extracting the data were previously trained on a separate cohort. Precision and recall calculated for each data attribute utilizing R programing language and statistical computing environment. The calculation of precision can be defined as an index to measure the accuracy or closeness of a measured value to a known value (also known as positive predictive value). Recall can be defined as a measure of ability to capture all data points of interest (true positive rate or sensitivity). F-measure combines precision and recall as a harmonic mean.
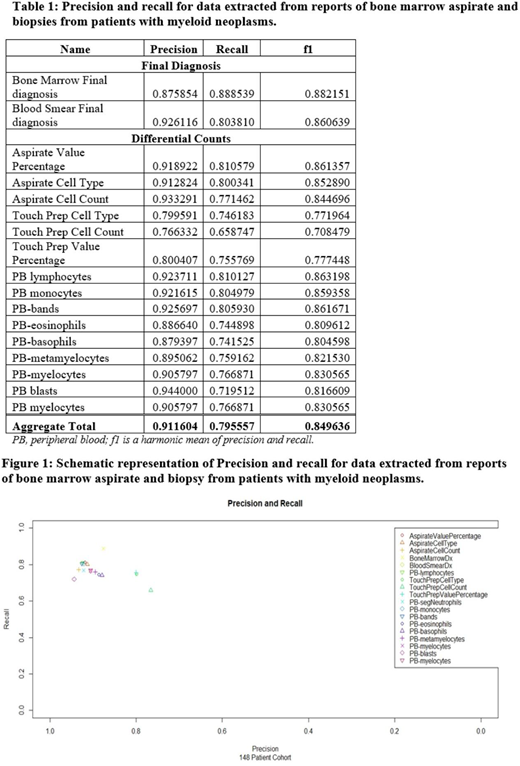
Results:Overall accuracy for the data captured was precision n = 0.9117 and recall n =0.7951. Precision and recall values for numerical and text data is reported in Table 1 and Figure 1.
Conclusion:Extraction of relevant diagnostic data from unstructured bone marrow biopsy reports through automated approach is feasible and accurate. This method saves time and can be utilized for automated extraction of unstructured pathology reports from patients with different hematologic malignancies. Capturing data and storing in structured formats will allow researchers to perform large-scale queries. At the Huntsman Cancer Institute, this data is stored in easily accessible database and linked to other databases such as tissue banking. This approach will allow physicians and translational researchers to find samples with specific diagnosis or molecular mutation, for example identifying AML patients with mutated FLT3 gene. Data on extraction of karyotype, FISH and molecular mutations is being analyzed for accuracy and will be presented at the meeting. Future work involves identifying and improving accuracy and expanding the algorithms to extract additional fields in bone marrow biopsies and apply these algorithms to other hematologic malignancies.
Deininger:Blueprint: Consultancy; Pfizer: Consultancy, Membership on an entity's Board of Directors or advisory committees.
This icon denotes a clinically relevant abstract

This feature is available to Subscribers Only
Sign In or Create an Account Close Modal